
Generating Text with Large Pre-Trained Language Models : Assignment 12
For this homework, we will combine ideas from the entire class: language models, vector-based word representations, and neural networks. We’ll be using large, pre-trained language models to generate text, and studying some of the biases that get encoded in to these kinds of models.
The current state-of-the-art models for a variety of natural language processing tasks belong to the Transformer Family, which are models based on the Transformer architecture. The Transformer can be thought of as a big feed-forward network, with some fancy bells and whistles such as the attention mechanism. You might be wondering: why are we moving back to feed-forward networks after such success with recurrent neural networks and variants like LSTMs? It turns out that although recurrent models are naturally poised to handle sequences as inputs, their non-serial nature makes them difficult to train in a distributed/parallel fashion. This means that serial networks can be trained faster, allowing orders of magnitude more training data to be used. Some examples of notable state-of-the-art Transformer based models are Google’s BERT, and Open AI’s GPT-2.
Learning Goals
The learning goals for this assignment are:
- An introduction to GPT-2, which is a large-scale language model that can be used to generate text that often sounds like it was written by a human.
- Learn to use the HuggingFace package to fine-tune GPT-2 to generate text that sounds like it was comes from a domain of interest.
- Examine the biases that are present in large-scale language models by looking at what BERT predicts for masked words when gendered pronouns or certain jobs are mentioned in a sentence.
Background: GPT-2
In 2018, OpenAI released a very impressive language model named GPT, which stands for Generative Pre-Training as the model makes heavy use of transfer learning. Transfer learning is using knowledge gained from one problem (or training setting), and applying it to another area or domain. The idea of transfer learning for NLP, is that we can train a language model on general texts, and then adapt it to use it for a specific task or domain that we’re interested in. This process is also called fine-tuning.
In 2019, OpenAI released a scaled-up version of their language model with an insane 1.5 billion parameters, called GPT-2. To train such a large model, OpenAI crawled 40GB worth of text from the web (roughly 20,000,000,000 words). GPT-2 is an extremely impressive language model that can generate text that often sounds so plausible that it seems like it might have been written by a human. Here is an example of what GPT-2 can generate, taken from OpenAI’s blog post:
Human-Written Prompt:
“Miley Cyrus was caught shoplifting from Abercrombie and Fitch on Hollywood Boulevard today.”
Model Continuation:
The 19-year-old singer was caught on camera being escorted out of the store by security guards.
The singer was wearing a black hoodie with the label ‘Blurred Lines’ on the front and ‘Fashion Police’ on the back.
Scroll down for video
Shoplifting: Miley Cyrus was caught shoplifting from Abercrombie and Fitch on Hollywood Boulevard today (pictured)
The singer was also wearing a pair of black-rimmed glasses, a black jacket, black jeans and black sandals.
She was carrying a pair of black and white striped gloves and a small black bag.
(To be clear: Miley Cyrus was never actually arrested for shoplifting). The quality of the model’s output was so good, that the researchers at OpenAI were worried that in addition to positive applications, it might be used for malicious purposes like generating fake news, impersonating people online, creating abusive or fake content to post on social media, or automating spam and phishing scams. In a demo to Wired Magazine, the reporter typed in “Hillary Clinton and George Soros” and GPT-2 generated a crazy rant with lots of conspiracy theories:
Hillary Clinton and George Soros are a perfect match, and their agenda appears to be to create a political movement where Soros and his political machine and Clinton are two of the only major players. This is the first time Soros and Clinton have been caught on tape directly colluding in promoting the same false narrative. One of the key revelations in the leaked audio was Clinton’s admission to a Russian banker that she knew about the Uranium One deal before it was approved by Congress. Clinton was shown sharing the same talking points that were originally drafted by a Fusion GPS contractor hired by an anti-Trump Republican donor. The leaked audio is the clearest evidence yet that the Clinton campaign and the Hillary Foundation colluded with Fusion GPS to manufacture propaganda against President Trump.
They were concerned enough that they labeled GPT-2 “too dangerous to release”, and OpenAI initially refused to release their dataset, training code, or GPT-2 model weights. OpenAI decided to release in a delayed, phased fashion so that researchers could spend time working on automatic detection of generated text.
Part 1: Text Generation with GPT-2 and HuggingFace
We have provided a Google Colab notebook that walks you through the process of fine-tuning GPT-2 to generate text to be like training examples that you provide. We will use the Transformers library from HuggingFace, which provide support for many Transformer-based language models like GPT-2, BERT, and variants of BERT.
Fine tuning the full GPT-2 model can take a long time on Colab. You might consider upgrading to Colab Pro, which costs $10/month.
For this assignment, your task is going to fine-tune a released version of GPT-2 on two datasets: a text adventure set that we give you, and on a dataset of your own choosing. The data set we have provided for you is based on stories in the style of Choose Your Own Adventure books that we downloaded from chooseyourstory.com. This data was used to train a super-cool AI based text-adventure game called AI Dungeon. CCB is kind of obsessed with this thing.
In addition to fine-tuning to our text adventure data, we’re asking to to create your own data set. It can be anything you like –Harry Potter fan fiction, Shakespeare, music lyrics– be creative and have fun. Preparing your own dataset will involve you downloading/cleaning text from the internet, or creating the dataset yourself. Remember to create the usual train/dev/test split for the data that you create! Include your dataset along with your submission on Gradescope, and describe the process of designing your dataset in your report.
The provided notebook generates text by randomly sampling the next word in proportion to its probability according to the model. One extension that we commonly use to get better generations is to truncate the distribution to only consider the top $k$ words. This is called top-k sampling and the value of $k$ is a hyperparameter that we can choose through the process of our experiments. This strategy intuitively makes sense, since words at the bottom of the distribution (i.e. with low and near-zero probabilities) probably won’t cause for better generation quality and we’re better off re-distributing the probability mass to more likely candidates.
Your Tasks
-
Fine-tune a GPT-2 model (any size is fine, but larger sizes are more fun!) on the provided text-adventure dataset using the example code. Note that training will take a while - training for one epoch using the default parameters takes approximately 25 min. Report the perplexities before and after fine-tuning and describe the trends of perplexity in your report. Generate a few samples before moving on to get a feel for the model.
-
Repeat 1) using a dataset you put together. Similarly, report perplexities before and after and a few generated samples.
-
The skeleton code uses top-$k$ sampling, with the $k$ parameter set to be 50. Experiment with different sampling strategies to generate text and include examples, as well as your own qualitative assessment of the outputs in your report.
-
Instead of having a leaderboard for this assignment, we will be awarding extra credit to the most subjectively interesting/funny/impressive generations. Submit your favorite 150-token generation as a PDF document on Gradescope to participate!
Report
-
Summarize fine-tuning results on the provided text-adventure dataset, including perplexities before fine-tuning and afterwards. Comment on the trend you observe. Include a few sample generations.
-
Describe the process of how you obtained your personal dataset, including any additional pre/post-processing steps that occurred. Comment on any difficulties that arose, and compare your data to the provided dataset, thinking about how you expect model results to change.
-
Summarize fine-tuning results on your personal dataset, including perplexities before fine-tuning and afterwards. Comment on how this trend differs from the results of Task 1. Include a few sample generations.
-
Experiment with different sampling strategies, including examples of the data your model produces. Include a brief analysis of the obtained results.
Part 2: Language Model Bias
One problem with machine learning models that are trained on large internet-based text corpora is that they exhibit biases that exist in the training data, for example gender bias. In this task, you will get the chance to uncover some of these biases on your own. Using this masked language model demo developed by our TA Sihao, explore the following questions. In order to use the demo, you need to copy the prompt into the “Mandatory sentence.” box, and keep the default selection as “per-token independent selections”. In your report, include observations in response to the following mini exploration tasks.
The demo visualizes the Masked LM objective of BERT. Given a input sentence, with some of the tokens masked or hidden, BERT will try to predict the likely words/sub-words for these positions. Here’s what the demo looks like:
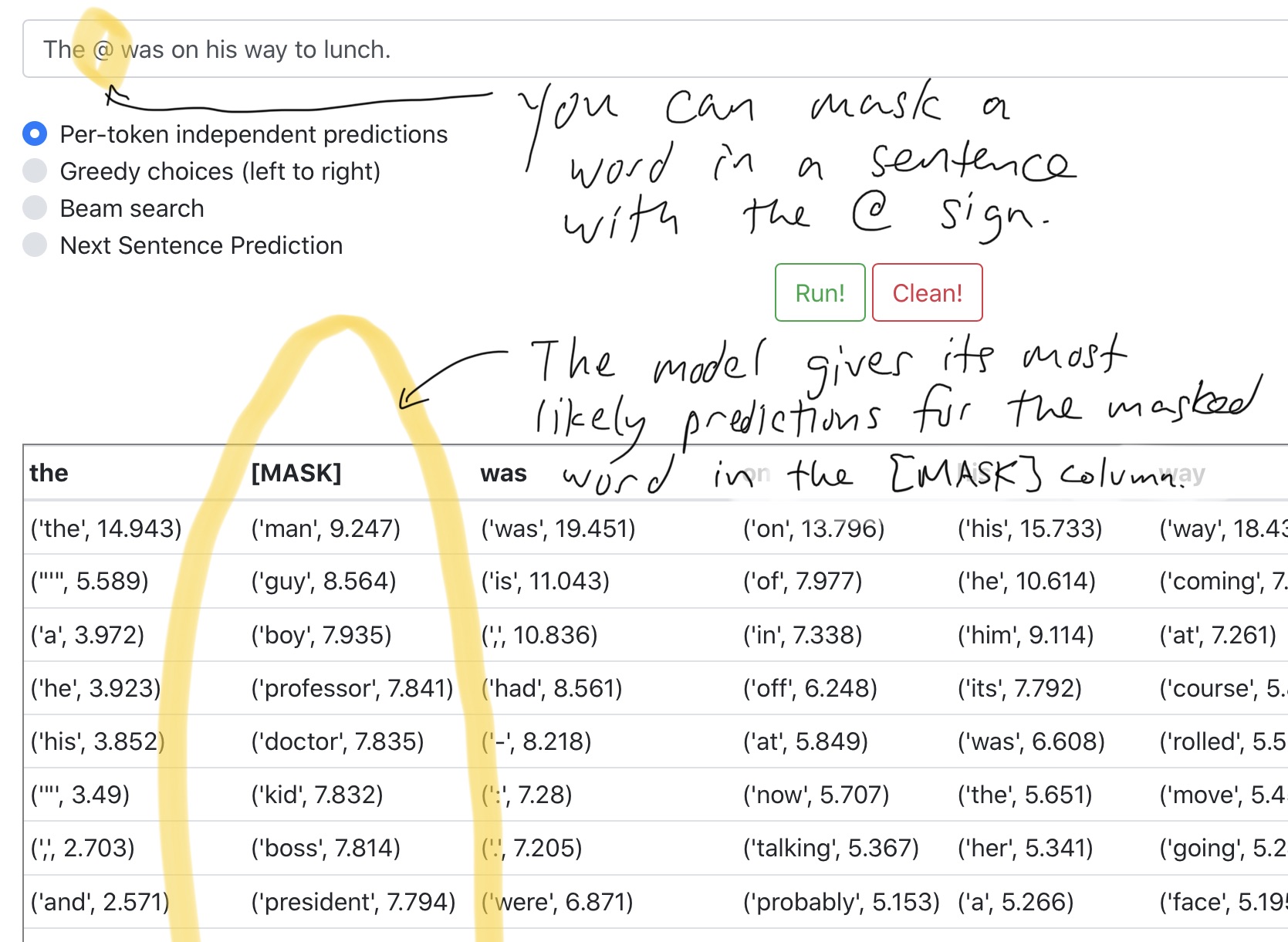
Each column shows a list predicted tokens for the word position, along with the predicted score/probability. To see the predictions, you should input a sentence in the “Mandatory sentence” field. The format is designed for sentence pair classification tasks (e.g. HW11).
You may notice that the BERT tokenizer adds a few special tokens to the input –
- “@” is a special mask token, for which you want the models to predict on. Notice that even without the mask token, you can get predictions at each word position as well. However, since the model can see the actual token if you don’t mask it, the prediction will be biased towards it.
- In the beginning of every input example, you will see a “[CLS]” token, which is a placeholder for class labels. In case you are using BERT for classification tasks (e.g. sentence pair classification tasks in HW11), this will be replaced by the corresponding label for each input example.
- “[SEP]” is a special token that indicates the start/end of sentence. A special token is needed because period (“.”) does not always mark the end of a sentence (e.g. there are periods in Acronyms).
- The Optional Sentence field allows you to input a second sentence to BERT, separated by the “[SEP]” token.
- You may have seen incomplete tokens which start with “##”. This is a special tokenization technique called word-piece or byte-pair encoding (A good explanation of it can be found here). It is designed to use the morphology of out-of-vocabulary words to induce their semantics.
Your Tasks
For this part of the assignment, there is no code to implement. All you have to do is explore the model’s output using the online demo. You should write up your findings for parts 1-4 below, and include them in your Report in a section that you should call “Part 2: Language Model Bias”.
-
Consider the prompt:
The @ was on his way to lunch.What are the top 5 most likely professions that the language model predicts? -
Now consider:
The @ was on her way to lunch.What are the top 5 most likely professions that the language model predicts? How do these compare to the previous list? -
Try doing the opposite - choose some profession, and mask the pronoun. For professions that have a clear male/female counterpart (i.e. nurse/doctor, actor/actress, etc.), note whether the predicted pronoun aligns with your notion of “male/female” roles (notice how easily we exhibit these same biases as well…). Could you find professions for which the pronoun predictions are less evidently biased?
Now, try to change the main structure of the sentence (i.e. move it away from the lunch theme) to encourage the model to give different pronoun predictions for the same profession. What do these results tell you? Is this easy or difficult to do? Does your setup work for different professions?
-
As a final step, explore biased pronoun prediction outside the scope of professions, for example in the scope of activities (or whatever else interests you). Are there activities you expect to be more gender-neutral than they actually are based on the language model predictions? Are there any particularly surprising examples that stood out to you? Experiment to the degree you find interesting, and briefly summarize your findings in the report.
This is an open problem in natural language processing research: mitigating the uncontrollability of language models.
Deliverables
Here are the deliverables that you will need to submit:
- Code (as a downloaded Colab notebook)
- Your compiled dataset, including train/dev/test splits
- PDF report with analyses for Part 1 and Part 2 of this assignment
- One favorite 150-token generation sample from Part 1
Recommended readings
|
Language Models are Unsupervised Multitask Learners.
Radford, Alec, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever.
OpenAI Blog .
Abstract
|
|
BERT: Pre-training of deep bidirectional transformers for language understanding.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova.
NAACL .
Abstract
|
|
Automatic Detection of Generated Text is Easiest when Humans are Fooled.
Daphne Ippolito, Daniel Duckworth, Chris Callison-Burch, Douglas Eck.
ACL .
Abstract
|
| The Illustrated GPT-2 (Visualizing Transformer Language Models). Jay Alammar. Blog post . |
| The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning). Jay Alammar. Blog post . |