
Perspective Detection : Assignment 11
When you ask Google question in natural language it attempts to get you a single correct answer. This is great for questions like What temperature is recommended for salmon? but it fails on questions for which there isn’t a single correct answer like Should uniforms be required in schools?:
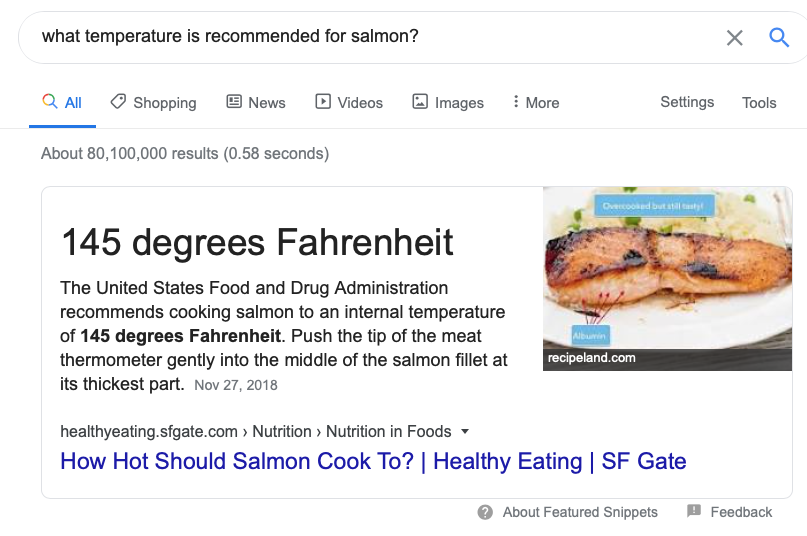
|
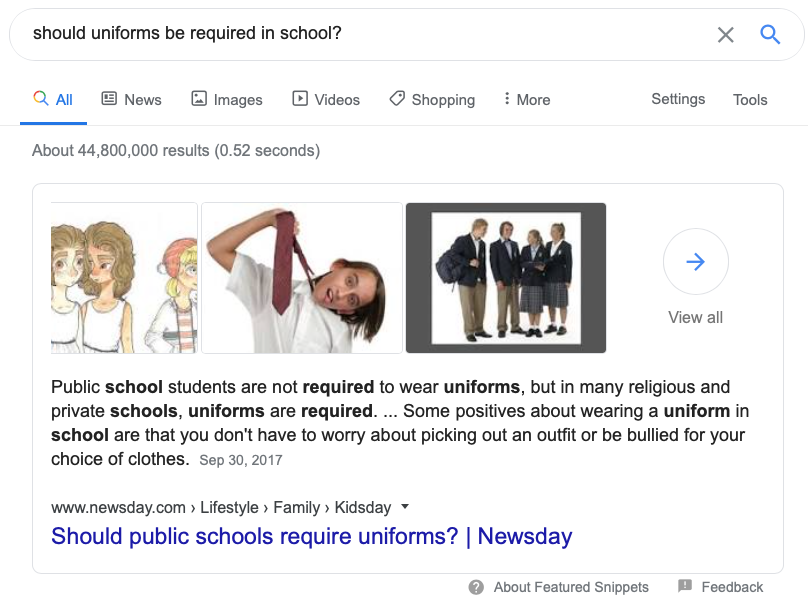
|
In questions like Should uniforms be required in schools?, users are seeking multiple perspectives on a topic. Ideally, we should organize potential answers to such perspective-seeking queries into two sets: perspctives that support an idea, and perspectives that refute it.
As part of his PhD research, your TA Sihao built a demonstration search engine called PerspectroScope. Given a claim as input, PerspectroScope will look for potential perspectives on the web, and use classifiers trained on a dataset called Perspectrum to decide whether each potential perspctive is relevant and whether it is supports or opposes the claim. Here’s an example of Sihao’s search engine organizes perspectives related to animal rights:
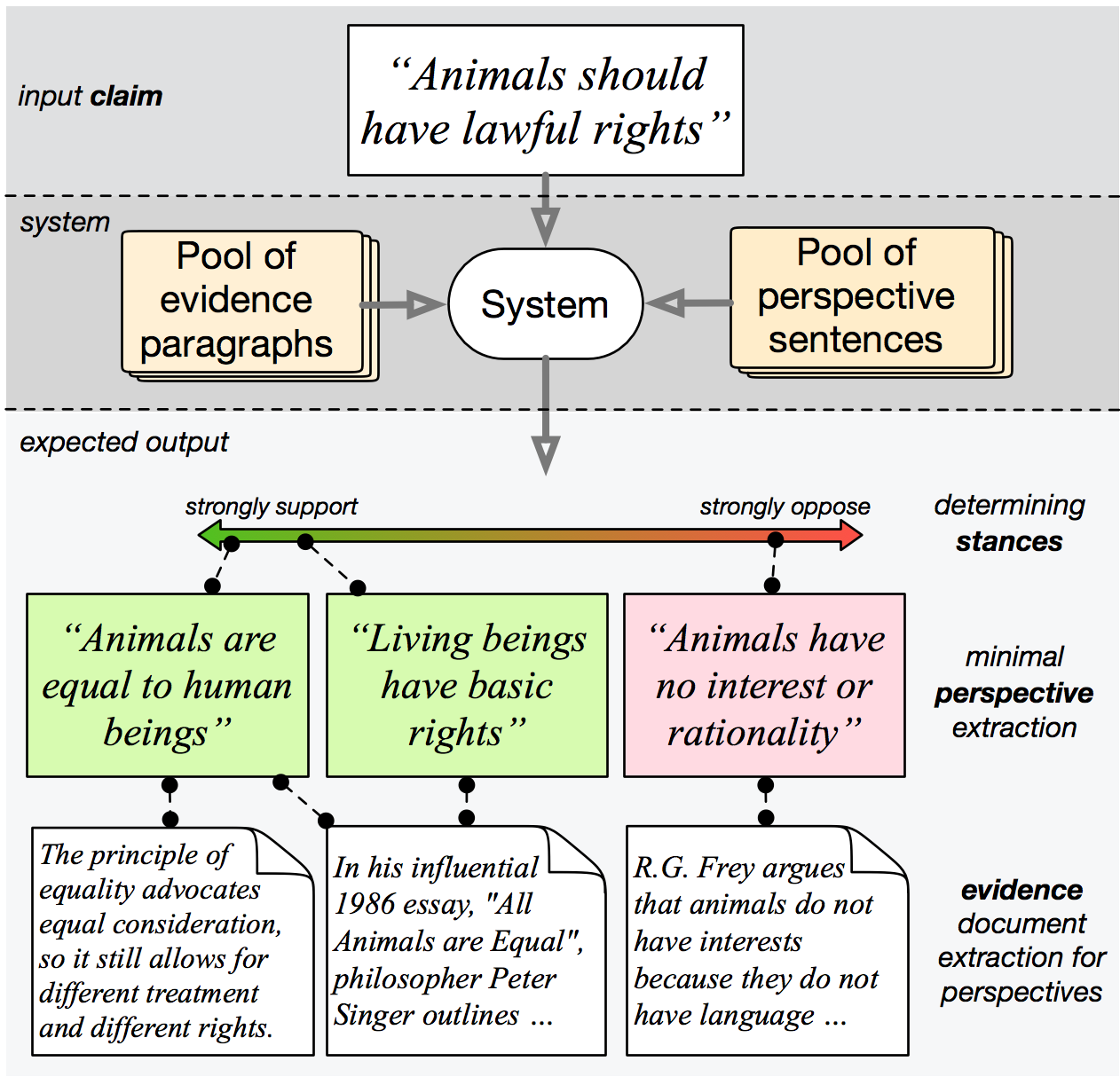
Here is a youtube video that demonstrates the functionality of the search engine. You are also welcomed to try the search engine yourself.
Learning Goals
The learning goals for this assignment are:
- An introduction to BERT, which is a powerful architecture that can be used to solve many NLP tasks. BERT is a large, pre-trained neural language model based on the Transformer architecture that can adapted to many classification tasks.
- Learn how to solve sentence pair classification tasks by “fine-tuning” BERT to the task. The process of fine-tuning adapts a general pre-trained model like BERT to a specific task that you’re interested in.
- We’re going to fine-tune BERT to do two important classification tasks that play a part of the perspective search engine:
- Relevance Classification: Given a claim and a perspective sentence, classify whether the sentence presents a relevant perspective to the claim.
- Stance Classification (extra credit): Given a claim and a sentence of relevant perspective, classify whether the perspective supports or refutes the claim.
Background: BERT
For this assignment, we are going to use BERT. BERT is a state-of-the-art neural language model that was released in 2019 by Google Research. BERT is an acronym for Bidirectional Encoder Representations from Transformers. It can be used as an encoder to produce sentence embeddings, and to produce context-based word embeddings. Models trained using BERT embeddings (or variants of BERT) have been producing state-of-the-art results across most NLP task recently.
Like the word embeddings (e.g. Word2Vec, GloVe) that you have played with in a few of the past homework assignments, BERT is trained with similar, but slightly more sophisticated learning objectives – The first objective is known as Masked Language Modeling (MLM), where we randomly “mask” a certain fraction of words from a text during training and have the model predict the masked words. The second task objective Next Sentence Prediction (NSP) – given two sentences, predict whether the second sentence comes after the first sentence in natural text.
There are several things that make BERT so good:
-
Contextual: A key difference between word embeddings and BERT is that BERT is contextual, which means it is producing embedding based on not only the word itself, but also the context it appears in. That way, the BERT embedding for each word is “dynamic”, and will change based on the context it appears in. Such features allow BERT to capture various linguistics phenomena like word sense disambiguation.
-
Number of Parameters and Scale of Training: BERT is huge. The base version of BERT (12 layers of transformers) consists of 110M parameters, and is trained on 800,000,000 words.
-
Fine-tuning: Fine-tuning is a process to take a machine learning model that has already been trained for a given task/objective, and further train the model with a second similar task/objective. When you train models with BERT embeddings for downstream tasks, the entire BERT model’s weights are updated during training, and so the BERT embeddings are “adapted” according to the task at hand. On contrary, when you use word embedding, you don’t actually update the part of the network that was used to train the word embeddings. This process is called “BERT fine-tuning”. The ability of fine-tuning makes BERT more expressive, and easier to adapt to the task-specific supervision. In this homework we will show you a step-by-step process of BERT fine-tuning.
For more information on BERT, we recommend watching this guest lecture for CIS 530 by Jacob Devlin from Spring 2019. Jacob was the lead author on the original BERT paper.
Sentence Pair Classification
Sentence pair classification is the task of classifying what relation holds between a pair of sentences. Many popular tasks in NLP can be viewed as examples of sentence pair classification. E.g. Almost every task in the GLUE Benchmark – a collection of datasets for evaluating a model’s capability of “language understanding”.
BERT has been shown to be very effective for sentence pair classification. For the rest of this homework, we are going to introduce and work on one of such tasks as example.
Part 1: Relevance Classification via BERT fine-tuning
For this part, we will show you how to build a BERT-based sentence pair classifer for Perspective Relevance Classification.
To help you understand what the task is about. Here’s an example in perspectrum_train.json: For each given claim, there are a few perspectives that either supports or refutes the claim. All these “perspectives” are relevant arguments to the claim. However, if you are building an search engine that searches for such perspectives on the open web, you will be needing a classfier, which, given a claim, can detect whether a sentence is a relevant argument to the claim or not. Note that a challenge here is – we don’t have negative examples provided. So we will be doing negative sampling to get unrelated perspectives for training.
{
"cid": 188,
"claim_text": "We must grant those diagnosed with terminal illnesses the right to access treatments that have not completed clinical testing",
"perspective_for": [
{
"id": 1397,
"text": "It is cruel to deny people the last hope"
},
{
"id": 22189,
"text": "It is amoral to deny terminal patients last hope treatments"
},
...
],
"perspective_against": [
{
"id": 1400,
"text": "This gives people false hope"
},
{
"id": 22193,
"text": "Terminally ill patients would be getting false hope"
},
...
]
}
We would like you to follow the notebook, and understand how each step works when training (or fine-tuning) a BERT-based sentence pair classifier for the task. Roughly there are 5 steps to the whole procedure. The code for step 1-4 is already given to you in the notebook. You will need to implement the last step, which should be very similar to step 4.
- Convert the training dataset into sentence pair format. Sample negative examples (i.e. arguments/perspectives not relevant to the input claim) for training.
- Preprocess data and extract features as input to BERT
- Intialize BERT model and Fine-tune BERT with positive and negative sentence pairs
- Evaluate on the dev set to get a performance of the model
- Predict on the test set, where the labels are hidden from you.
The goal for this part is to get yourself familiar with PyTorch/BERT through examples. These steps are common to developing Neural Network models for most sentence-level NLP tasks, and should give you a general idea on how you would train/evaluate a BERT-based classifier. Feel free to improve or build upon the example code if you are interested in using it for other tasks.
Follow instructions and submit your model’s prediction on the test data; store the predictions in a file named relevance_test_predictions.txt, and submit the file.
Important Note: the labels of the test data are NOT given to you in this homework. However the helper functions will still generate a dummy label for each input sentence pair. The only way to measure the correct accuracy on test set is submitting your test results relevance_test_predictions.txt to Gradescope.
Part 2: DIY - Stance Classification (Optional, Extra Credit)
Now that you have seen an example, and hopefully are becoming an expert of BERT, let’s try to follow similar steps and tackle the stance classification. Given a claim and a relevant perspective, classify whether the perspective supports or refutes the claim.
For the most part we expect you to be re-using code from Part 1. Since this is a different task, you will be doing step 1 (generating positive and negative sentence pairs) in a slightly different way; Specifically –
-
In
perspectrum_train.json, for each given claim, both supporting and refuting perspectives have been given to you. So you don’t need to do negative sampling. Instead you should take the claim + “supporting” perspective as positive sentence pair and claim with “refuting” perspective as negative pair. -
The task assumes that for every input claim-perspective pair, the perspective is relevant to the claim. So when generating training pairs, you should make sure of that.
Submit your model’s prediction on the test data; store the predictions in a file named stance_test_predictions.txt, and submit the file.
Part 3: Improving your classifier(s)
The model setup provided in the default skeleton will not give you nice results on the test set. For this part, we would like you to implement at least three types of modifications/additions to the provided baseline, and include your findings (e.g. results on dev set) in the final report.
There are leaderboards for both relevance and stance classification tasks. Please submit relevance_test_predictions.txt (required) and (optional) stance_test_predictions.txt for entry to the leaderboard, and see your score on the test set.
Here are some ideas for improvements:
- Increase the number of transformer layers for BERT. In the colab notebook, we are using a mini version of BERT, which consists of 4 layers of transformer. The base version of BERT has 12 layers, which will give way better performance, at the cost of longer training/evaluation time.
- Use other variants of BERT (E.g. ALBERT, RoBERTa). You can find a more-than-enough list of available models from the README of huggingface transformer package.
- For the relevance classification task, you can adopt better negative sampling strategies for training – We’ve previously ask you to sample negative examples randomly. For example, a better negative example would be, perspectives not related to the claim, but have significant word overlap (e.g. it’s discussing similar topics, but it’s not an valid argument towards the claim).
- Parameter Tuning: In the skeleton code, we have listed a suggested range of hyperparameter (e.g. different learning rates and batch sizes). You are welcomed to try different values for each hyperparameter, and report your findings!
Report
As usual we want you to keep track of all experiments and findings in your report. But here are the list of things that we are looking for (and will grade the report on).
- You should make at least three modifications/extension to the baseline model and explain what you did.
- For each modification, specify the size and the type of the BERT model you use, plus the hyper-parameters you chose for training. Include the performance on the dev set for each configuration.
- Using the best performing model on dev set, identify a few mistakes that the model makes on dev set. Include a few of such claim/perspective pairs in the report and briefly describe the mistake and why you think the model produces the wrong prediction.
- Write a few sentences on what you think makes the Perspective Detection task challenging. (Note that there isn’t a single correct answer to the question; we are interested in knowing your perspective!)
Deliverables
Here are the deliverables that you will need to submit:
- Your notebook, downloaded and named as
perspectrum.py. You can download your notebook as a.pyfile by going to the menu bar: “File” -> “Download .py”. - Results on the test sets of Relevance or Stance classification task, named
relevance_test_predictions.txtandstance_test_predictions.txtrespectively. - PDF Report (called writeup.pdf)
Recommended readings
| BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Jacob Devlin. Guest Lecture for CIS 530, Spring 2019 . |
|
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova.
NAACL 2019.
Abstract
|
|
Seeing Things from a Different Angle: Discovering Diverse Perspectives about Claims.
Sihao Chen, Daniel Khashabi, Wenpeng Yin, Chris Callison-Burch and Dan Roth.
NAACL 2019.
Abstract
|
|
PerspectroScope: A Window to the World of Diverse Perspectives.
Sihao Chen, Daniel Khashabi, Chris Callison-Burch and Dan Roth.
ACL 2019.
Abstract
|