
Basic bash for NLP tutorial
Bash is a language that allows for easy manipulation of Unix-like computing environments.
Frequently in NLP research, quick simple tasks like “how many lines are there in this file” or “how can I copy a file to 100 places at the same time” arise, and can best be solved with bash, and some easily-usable affiliate programs.
Beyond this, Bash is much more versatile and useful than many give it credit for, and advanced knowledge of bash can make projects involving very large systems and/or multi-step pipelines truly a joy.
When to use bash; When not to
I love bash dearly. That’s not to say it’s the answer to every problem in NLP.
Use bash when
- You need to move, and/or rename one or many files
- You need to set up folder structures, create symbolic links (more on this later), and generally change the file system.
- You want basic statistics on one or many files (e.g. “I have 3,000,000 lines of log files, and if the word ‘error’ appears, something failed. Did it ever appear?”)
- You want to submit multiple jobs to the scheduler with similar parameters
- You want to set up a “pipeline”, which means a set of processing steps that takes input files and produces output files, using multiple independent programs.
Don’t use bash when
- You need to do a lot of arithmetic computation, especially division/multiplication
- You need library support (for, say, reading TSVs, or JSON, etc.)
- You plan to make copious use of fun data structures like sets, counters, UnionFind, MyArbitraryClass, or TrieHeapMapBellmanFordImpl
File system and unix basics
As we said in use bash when, we frequently use bash to manipulate a Unix file system.
The unix filesystem is a rooted tree-like data structure. Its root is /. This forward slash is known as “root”. Below is a diagram showing a selection of the root of the nlpgrid filesystem(s).
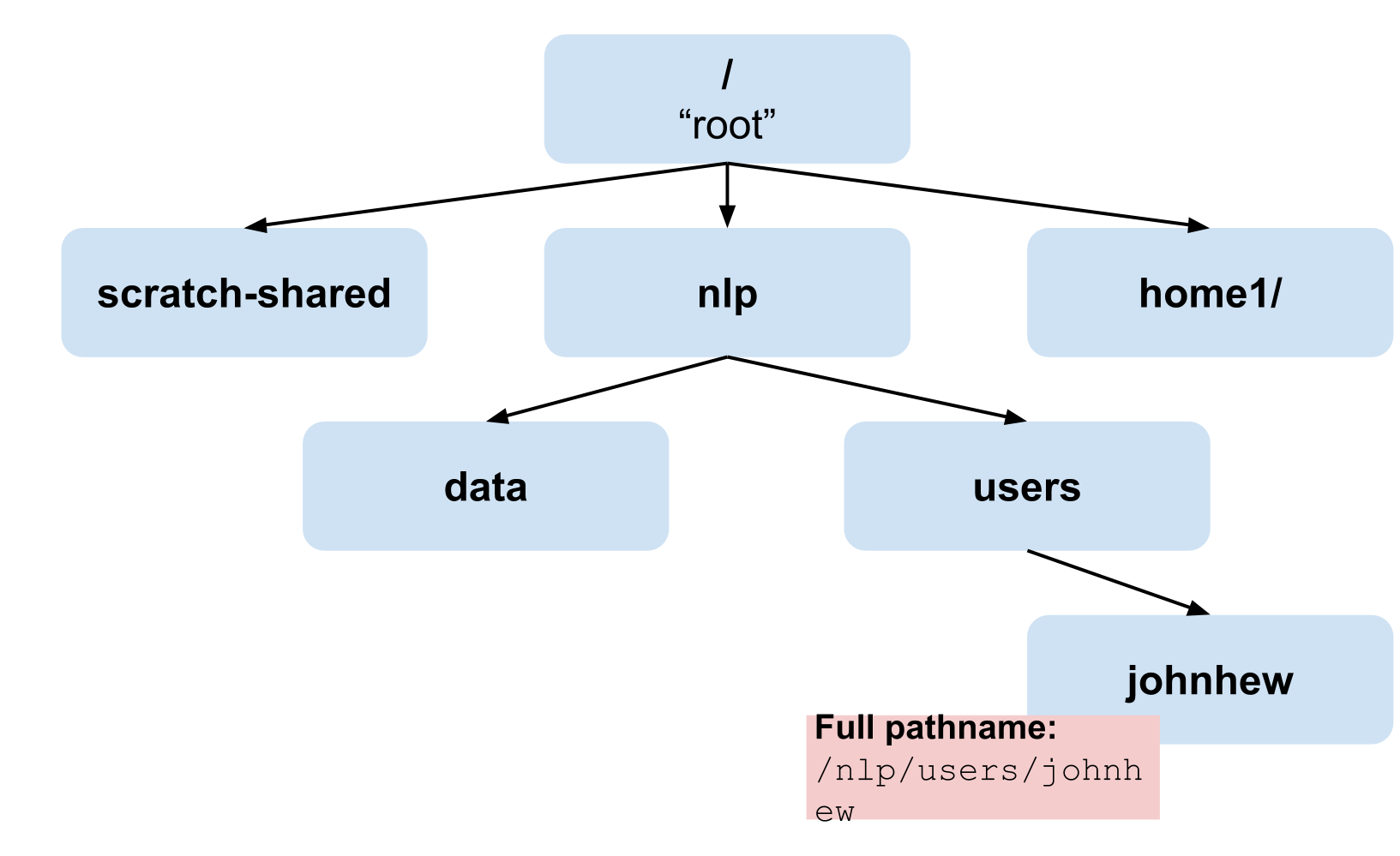
When using bash, you are always “at” one of the nodes in the filesystem tree.
Every command you run is run relative to your current node, or “folder”, or more commonly, “directory.”
A “path” is a list of names of folders combined with forward slashes (/) that takes you either from root (an absolute path) or from any arbitrary directory (a relative path) to some other directory.
Knowing where you are
When running bash commands, ., the period, corresponds to your current directory.
When reading or writing files, the . is implicit. Let’s demonstrate this with a file.
Open up a terminal and run
touch testfile
This creates a file named testfile if it doesn’t exist, or updates the ‘last-read’ flag on the file if it already existed.
Now, list the contents of your current directory with
ls
You should see (possibly among other things) the file testfile.
You can demonstrate that this is equivalent to:
touch ./testfile
ls .
In both cases, the . was implicit.
However, when specifying commands, the . is not implicit. For example, try running
./touch testfile
You should find that bash complains with a command-not-found error.
This is because you told bash “look for the command touch; it’ll be in this directory.”
Without the prepended ./, the command touch is found by other means, which we’ll find later.
Specifying the location of files you want to work with can be more complex than just looking in your current directory, however. For example, make a directory within your current directory with
mkdir testfolder
Now, make a new file in that directory, and demonstrate that the file is in the directory, with
touch testfolder/testfile2
ls testfolder
You can also change your working directory, which changes the location from which your commands are run. For example, if we run
cd testfolder
ls
We should see testfile2, not testfile. To return to the directory just 1 “above” (or, closer to /) from the current directory, run
cd ..
Where .. is short for “parent directory”.
Directory navigation quick tips
Here are some other quick commands you’d otherwise have to search for at some point:
cd -sends you to the last directory you were in, whatever that was, and prints the name of that directory.~the tilde represents your “home” directory. On my laptop, for example, thats/home/johnhew. If you run a command with the tilde, it will be replaced by the location of your home diretory.*the asterisc stands for “everything within the directory I’ve just specified”. Thusls *means “list the contents of every file/directory in the current directory.”pwdis a command that prints the absolute path of the current working directorytreeis a fun commands that lists the tree structure starting from the current working directory and searching “down” (away from/).
File copying and movement
To copy a file located at oldloc to a new location newloc, use the `cp command as follows:
cp oldloc newloc
Seems simple enough. oldloc and newloc can each be an absolute path, like /nlp/data/johnhew/expts/realgooddata.txt.png, or a relative path like realgooddata.txt.png.
The semantics of cp allows you to copy multiple files to one location, but not copy 1 file to multiple locations. By this I mean when you run:
cp loc1 loc2 loc3 loc4 loc5
You’re copying loc1 through loc4 all into loc5. If loc5 is a directory and loc1,loc2,loc3,loc4 all have unique filenames, all 4 files will be copied into the loc5 directory.
If loc5 is a file (or didn’t exist previously), each file will be copied sequentially into loc5, squashing all old files. In other words, all you’ll end up with at loc5 is (in this case) loc4.
If you don’t want to keep the old file locations, use the mv (move) command instead of cp.
Reading, editing, analyzing files
Moving files is great, but actually working with files contents is great too.
An optional aside : vim
To integrate file editing into your bash workflow, I highly suggest putting in the time to learn vim, the world’s best text editor.
There’s a bit of a learning curve, but many things are googleable, and I’ll start you off with two things:
- Use
:qto quit. -
Here’s a good starter
vimrc, which is a configuration file. Google for more info.filetype indent on filetype plugin on set expandtab set mouse=a set pastetoggle=<F2> syntax enable set tabstop=2 set shiftwidth=2 set softtabstop=2 set autoindent set whichwrap+=<,>,h,l,[,] set cursorline set number set hlsearch set lazyredraw set omnifunc=syntaxcomplete#Complete set grepprg=grep\ -nH\ $*
Printing and streams
To pring a file’s contents, run the cat command. (This stands for “concatentate”. If you run cat on multiple files, it prints them all out, one after the other.)
cat file1 file2 file3
What we’ve siad so far about “printing” has been pretty self-evident: text shows up in your bash terminal.
However, it is useful to know a bit more about how this works.
Any program has access to two “streams”, known as stdout and stderr, for “standard output” and “standard error”.
(To learn more about their true nature, take CIS 380 : Operating Systems.)
When a program prints, it writes data to stdout. By default, stdout is printed to your terminal (as is stderr.)
However, we can “redirect” these streams to, for example, concatentate 3 files:
cat file1 file2 file3 > fileall
This has just printed all of files 1,2,3 into the file fileall. The > character is called a “redirection”; it
redirects the stdout stream to the file specified after it.
Streams quick tips
-
to redirect
stdoutnot to a file, but to another program, use a pipe,|, as such:cat file1 file2 file3 | sort | uniq - to redirect
stderr, use the following:2> -
to redirect
stdoutto a file, but also see the output on your terminal, use theteecommand, as follows:cat file1 file2 file3 | tee fileall
Searching and analysis
To search for a string string within files file1, file2, file3, use the program grep as follows:
grep string file1 file2 file3
This will print out lines in each file that have the string string.
If your string has a space in it, you must enclose it in quotes (either single or double,) as in:
grep "error happened" file1 file2 file3
Grep is more powerful than this; instead of using a string, you can search for an arbitrary pattern, described by Regular Expressions.
(That’s worth a tutorial in itself.)
To count “things” in a file, use the program wc as follows:
wc file1
This will print the number of characters, number of words (whitespace-delimited) and number of lines in the file.
Similarly, you can run both wc and grep on output piped from some other process, as in:
cat file1 file2 file3 | sort | uniq | grep "error found"
cat file1 file2 file3 | sort | uniq | grep "error found" | wc
wc and grep quick tips:
grep -cwill print the number of lines that matched, instead of the lines themselves. This is equivalent to piping throughwc -l.grep -nwill print the line numbers of the matching lines (along with the matching lines)grep -r pattern dirwill recursively grep through a given directorydir.wc -wwill just give the word count, similarlywc -lwill just give the line count.
Shortcuts and efficiency
Working with files in bash can be much faster than using a GUI. These shortcuts will help you get up to speed.
Tab completion
Typing out long paths and filenames is very tedious, and prone to error. Bash provides a solution to both of these problems in “tab completion”.
As you type a file name, bash knows all the files in the directory you’ve specified so far, and knows which files you could be referring to, based on the prefix you’ve written so far.
At any time as you’re writing a filename, if you press <tab>, bash will determine whether it can unambiguously fill in any portion of the rest of the filename.
Let’s look at a few examples to make this concrete. In a new directory, type the following commands:
touch file1
touch file2
Now, type in vim fi and then hit <tab>.
Notice that bash completes to vim file without any work.
Because these were the only files in the directory, bash knew that when you wrote fi, you meant either file1 or file2. It won’t complete further than that because it can’t be sure which of the two you mean. So, you have to fill in the rest of the file name.
Note that if you have a directory with only one file in it, the empty prefix is unambiguous, and a <tab> completion will fill in the whole filename for you.
Further, use tab completion not only on files, but also on long directory paths. For example, instead of typing out all of
/nlp/users/johnhew/common-crawl/corpusplz/src/core/corpus_filter.py
I generally tend to write:
/nlp/u<tab>/joh<tab>/co<tab>/cor<tab>/src/c<tab>/cor<tab>
Even here, the forward slashes / aren’t typed by me, since the tab completion includes them, saving a lot of work.
Command history reverse-search
Typing out long lists of commands over and over again is a pain. Thankfully, bash includes a finite history of commands, and a nice search interface.
First, as you might figure out accidentally, pressing the up arrow key returns you to the last command you ran. This is very helpful, but scrolling through tons of commands to find something you ran yesterday can be tedious.
This is where the reverse-search comes in handy.
It allows you to search for commands in your history that include a substring you specify.
Type ctl-r in the terminal (hold ctl and press r), and you’ll notice your command prompt is replaced with (reverse-i-search). Now, type in a few letters that you remember were a part of the command, and it’ll search through your history to find the first command that matches your query.
For example, I might look for the last time I qsub‘d something to the scheduler with ctl-r followed by qsub.
If the first matching command isn’t what you’re looking for and you want to keep looking back through more matching commands, hit ctl-r subsequent times to move back through them.
A few notes:
- If you keep hitting
ctl-rand the command you see doesn’t change, or if you type in a prefix and you don’t see a matching command appear, it means you don’t have any (more) commands that match your query. - If you want to keep the command you found with reverse search, I tend to use the
escapekey. - Ify ou want to discard the command you found with reverse search, I tend to use
ctl-c.
Typing and modifying commands
Many “move my cursor to another position” tips are, unfortunately, operating system- (or desktop environment-) dependent. For example on linux with i3, I use ctl+left\_arrow or ctl+right\_arrow to move one word to the left or right in the commands I’m typing.
However, there are a few excellent shortcuts to cut your command typing time:
ctl+kerases everything from your cursor to the end of the line.ctl+ajumps your cursor to the start of the line.ctl+ejumps your cursor to the end of the line.ctl+wdeletes a word to the left of your cursor.
Note that you’ll have to get a feel for what a “word” means to bash. For example, whitespace separates words. Hyphens (-) do not separate words, and neither to underscores (_).
!-prefix
This one is dangerous; proceed with caution.
- !! runs the last command again,
!stringruns the last command that starts with `string again.!$runs the last word of the previous command.
Epilogue: compression
If you find files with the extension .tgz .tar.bz2, .tar.gz, never fear. These are your friends in the unix environment.
A tar file is an archive – that is, someone took a directory or a bunch of files, and stuck them together into one file for ease of transport.
A gzipped or bzipped file is a compressed file; that is, someone used awesome compression algorithms to make a single file take up less space on disk.
These strategies are frequently used together, leading to the file extensions seen above.
Let’s look at what do to:
-
“I have a
.tar.gz, and I want to get what’s inside it”tar xzvf file.tar.gz -
“I have a folder and/or some files
file1,directory3, etc. , and I want to make it into an archive:tar czvf file.tar.gz file1 file2 directory3 directory4 -
“I want to know what
xzvfandczvfmean”. Good question.-xmeans “extract” (i.e., from the archive).-zmeans “use gzip compression”-vmeans “be verbose; that is, tell me what files you’re working on compressing/extracting right now by printing their paths tostdout.”-fmeans “I’ll specify the file that you’re going to work with, and it’s coming up next.”
